Proof of Existence: High level overview
Proof of Existence on EmpowerChain is a feature designed to allow users to prove the existence of any document or piece of data at a specific point in time. This high-level overview will provide you with a brief explanation of the purpose, concepts, and implementation of the Proof of Existence module on EmpowerChain.
The main use case at first for proof of existence is for tracking data to be time-stamped and immutable.
Purpose
The main goal of the Proof of Existence module is to combine blockchain immutability with cryptographic hashing to enable users to:
- Prove that a specific piece of data existed at least at the time it was added to the blockchain.
- Demonstrate that the data has not changed since it was added to the blockchain.
This can be beneficial for various use cases (besides plastic waste tracking data immutability), such as demonstrating data or IP ownership, proving data integrity, and ensuring that data has not been corrupted.
What is proof existence?
Proof of Existence is a method that combines a hash and a timestamp to demonstrate the existence of a piece of data (e.g., a document, text, bytes) at a specific point in time. The blockchain's immutability ensures that the proof remains unchanged, allowing users to verify the existence and integrity of the data at any time.
Let's break it down into each of its components:
Hash(ing)
Hashing is a cryptographic function that converts a variably sized piece of data into a small, practically unique, fixed-size string.
This is done by taking a "variable length" input and mapping it to a "fixed length" output. The output is called a hash, and the function is called a hash function. In practice, it means that you can take any piece of data, no matter how large, and map it to a small string of characters. This also has the added benefit of being a one-way function, meaning that you can't take the hash and map it back to the original data.
Hash functions are non-deterministic in that similar data doesn't yield similar hashes; a minor change to the data will produce a completely different hash.
Hash functions are also deterministic, in that the same input will always produce the same output. These two things combined makes for an effective tool for verifying data integrity.
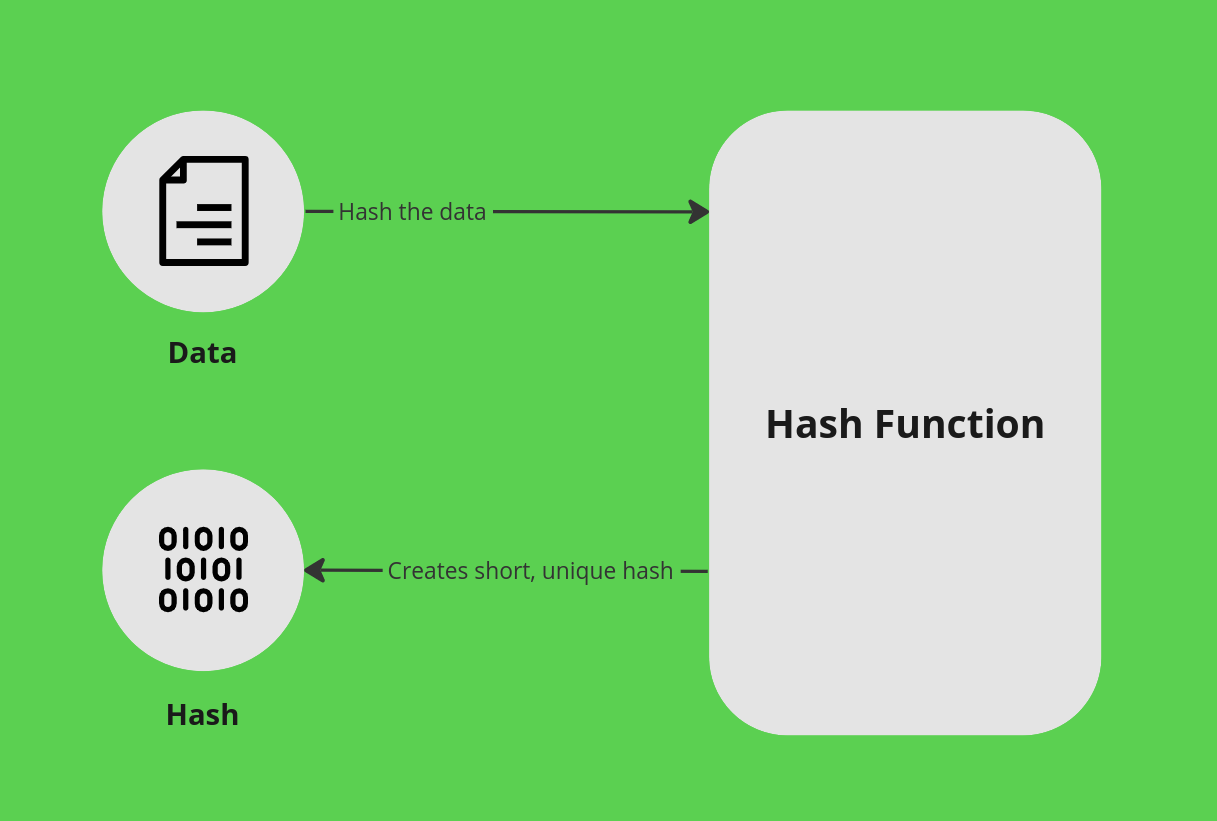
To prove data integrity, you simply need to run the data through the hash function and compare the output with the original hash. If the hashes match, the data is intact. If they don't match, the data has been changed in some way.
As an example, let's take the following "data" (read: text): "The quick brown fox jumps over the lazy dog" and put it through an SHA-256 hash function. The output is a 256-bit hash: d7a8fbb307d7809469ca9abcb0082e4f8d5651e46d3cdb762d02d0bf37c9e592 (the hash in HEX format). If just add a . (period) at the end of the text, you get a completely different hash: ef537f25c895bfa782526529a9b63d97aa631564d5d789c2b765448c8635fb6c.
Timestamp
Having a data integrity check is useful, but it doesn't prove that the data existed at a specific point in time (nor that you committed to that data). To do that, we need to add a timestamp and a commitment to the data.
Turns out that blockchain is pretty good at this. By storing the hash on the blockchain, we can prove that the data existed at least at the time it was added to the blockchain.
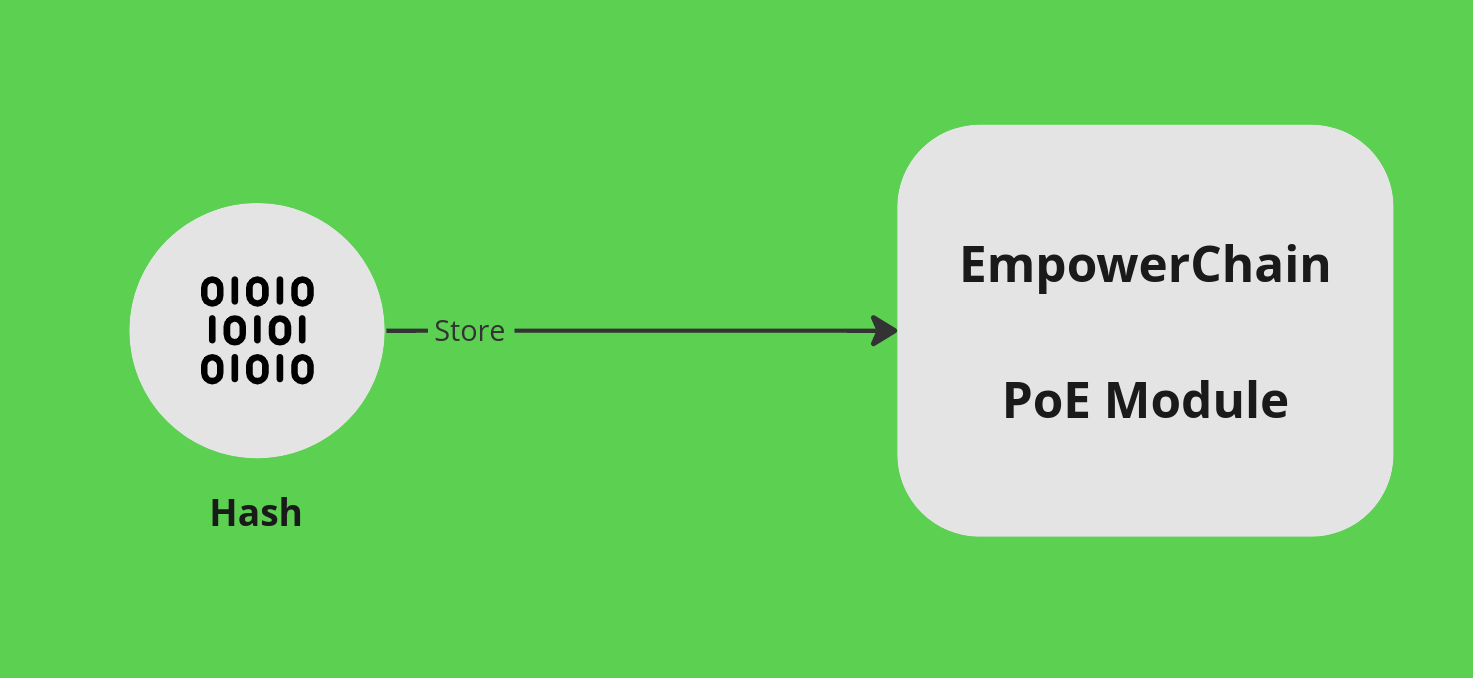
The Proof of Existence module on EmpowerChain is a simple, yet effective protocol for storing and timestamping a hash on the blockchain. The protocol does not allow for changing the hash or the timestamp, so you can be sure that the data existed at least at the time it was added to the blockchain.
Tying it all together
To prove that a piece of data existed at a specific point in time, we need to combine the hash and the timestamp. You simply follow the same procedure as mentioned already, but you also fetch the hash from the blockchain and compare it to the hash of the data you want to prove.
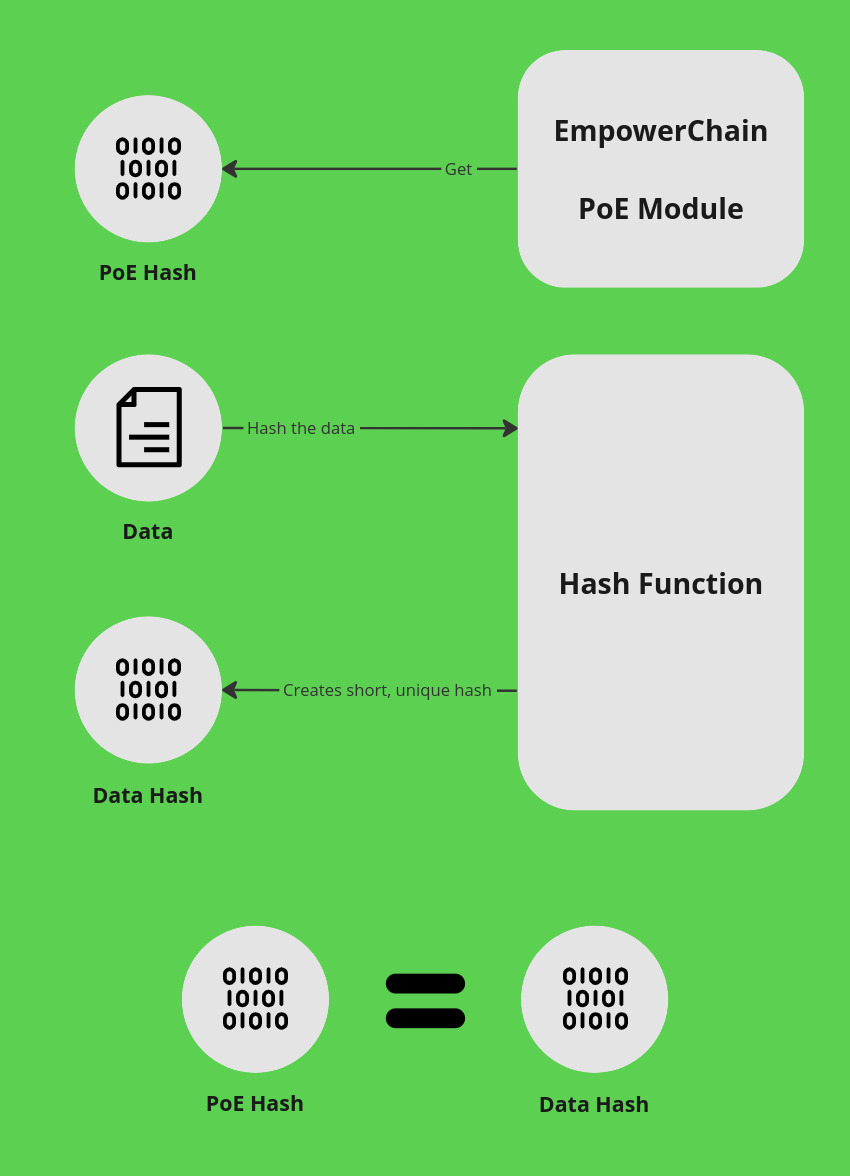
If the hashes match, you can be sure that the data existed at least at the time it was added to the blockchain. If they don't match, the data has been changed in some way.
A note one hash collision
Whenever you map something large (or at least larger than the output) into something small there will also be the theoretical possibility of collisions, where two different datasets yield the same result. In other words it is theoretically possible to have one hash function as the correct proof for more than one set of data.
To illustrate this we can take as example the widely used SHA-256 hashing algorithm: It produces a hash made out of 32 bytes (1 byte is 8 bits, so a total of 256 bits - 0s and 1s) and each byte can each represent 256 different values. The total number of possible permutations under SHA-256 then becomes 32^256. That is such an absurdly large number (it is a number so large that it has 386 digits and is more than 10^56 (or just about 3 septendecillion) times larger than the number of atoms in the universe) that any practical chances of a collision is just about inconceivable.
Read more
You can find more in-depth technical details on the implementation of proof of existence in the proof of existence module docs